Tools like Google Scholar, Zotero/Mendeley are now well known research tools.
But with the rise of open access papers , open data and machine learning techniques, new tools are starting to emerge ….. These are some of the most interesting ones I’ve seen in the past 2 years, that I think are worth looking into
- Keyword based delivery search — Dimensions & Microsoft academic
2. Browser extensions for delivery — Google Scholar button, Lazy Scholar, Unpaywall, Open Access button, Kopernio , Lean Library browser (not free), Anywhere access (not free)
3. Research literature clustering — Open Knowledge Map, Citation Gecko, Yewno (not free)
4. Reference management and reference extraction — ZoteroBib, F1000workspace, Pubchase, Scholarcy
5. Statistical software — JASP alternative Jamovi
6. Data cleaning — OpenRefine, Trifica Wrangler, Talend Data Preparation
7. Machine learning — Orange, Weka, Rattle , RapidMiner
8. Bonus — convert graphs in images to data — Web PlotDigitizer
1. Keyword based delivery search engine — Dimensions & Microsoft Academic
Pretty much everyone now uses Google Scholar for discovery and why not? It has the biggest index of Scholarly material in the world, almost impeccable coverage of free to read articles (arguably the gold standard for this), all wrapped up in a state of art relevancy system we expect of Google.
Still, Google Scholar isn’t without weaknesses, and while it’s feature set has improved lately , particularly with a recommender system, it still is lacking a little in the post filtering area.

While you can do advanced searches to filter by author (or use author:authorname), or by publication (or use source:journaltitle), Google Scholar lacks post-filters/facets for them.
This lack means that when you run a search, you can’t at a glance see who are the top authors or publications for that search.
Also as good as Google Scholar’s relevancy ranking is there are times when you want to filter to a specific discipline or to works by researchers from a specific institution.
The two free tools that you might use that make up for this lack is Microsoft Academic and Digital Science’s Dimensions , while neither are as big as Google Scholar , both are more than big enough . Dimensions has 95 million items and Microsoft Academic is even larger coming close to Google Scholar even when it was just a year old.
But when using those two tools it isn’t about size , it about features and both trump Google Scholar in terms of facets and filters.
Want to see what are the journals that publish papers that mention “Google Scholar” in their title or abstract? With Dimensions you can

You can do the same with Researcher as well. Also notice the cool “analytical view” panel on the right.
Most of the facets in Dimensions are self explanatory, such as “publication year” and “researcher”. Fields of research would be topics (more granular than disciplines like Sociology) and Open Access would be articles that are open access.
You might be wondering about “Journal List”.
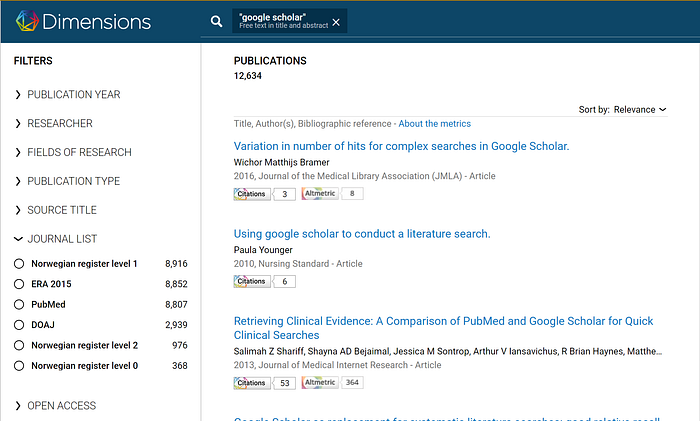
One of the drawbacks of all inclusive indexes like Google Scholar, Dimensions and Microsoft academic is that they take an all-inclusive approach unlike Scopus or Web of Science that carefully curate what journals are included.
The Journal List facet in Dimensions allow you to simulate that by limiting the results to subsets of journals such as those in PubMed and national lists such as the Australian ERA 2015.
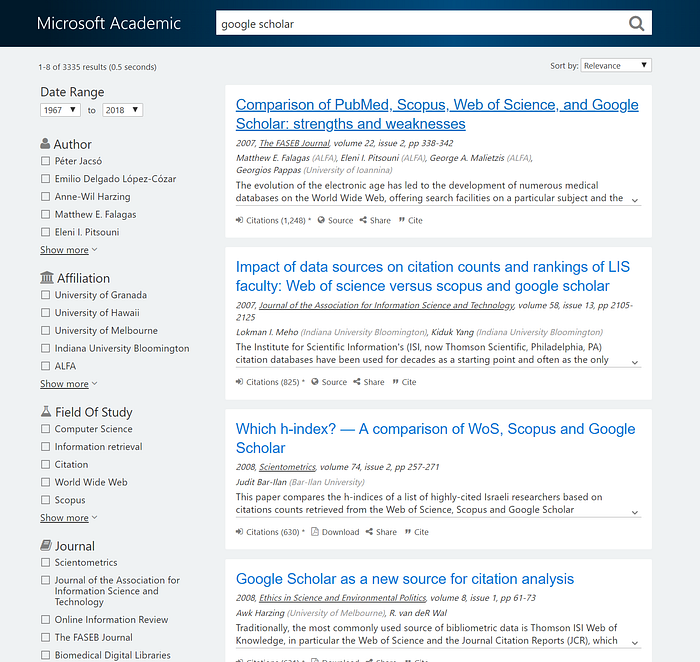
Of the two Dimensions and Microsoft academic, I suspect Microsoft academic is possibly even closer to Google Scholar under the hood relying more on automated full text extraction from harvested pages and pdfs than on existing metadata sources such as Crossref/Pubmed (Dimensions relies on Crossref data as a base but also does full text pdf processing from partners).
If so, you can’t tell from the interface. Like Dimensions you get plenty of facets to use. The main difference is that you get the affiliations facet in Microsoft Academic, while this facet isn’t available in the free version of Dimensions.
Others to consider : You should check if your institution has subscribed to an institution version of Dimensions which gives you more features. 1Findr is interesting but the free version only covers free full text, but if you have access to the institutional version it is worth looking at. Other large indexes in the same class are BASE , CORE, Lens
2. Browser extension based delivery
As the level of free to read article exploded in the past few years, checking for these articles as become a important part of a reseacher workflow. Sure you can use Google Scholar with it’s great ability to link to free full text or the institutional version via the library links programme , this doesn’t cover every use case.
You may land on a publisher page via email, Google or following a link on a blog. How do you quickly check what your options are be it a free copy or one via your institution?
Currently the most popular way to do so is to install the extension and it will either autodetect (or you press the extension button) and point you to a suitable version.
Not familiar with the idea? Watch this demo on use of Unpaywall browser extension , one of the most popular browser extensions with this function.
Currently there are a number of such extensions with slightly different functionality (e.g. some offer inter-library and document delivery services if no free or subscribed versions are possible), but here’s how I see them.
A) Covers free to read versions only
- Unpaywall
- Open Access button
- Lean Library browser (free version)
B) Covers both free to read version AND institution edition
- Google Scholar button
- Lazy Scholar
- Kopernio
- Lean Library browser (your institution needs to subscribe)
- Anywhere Access(your institution needs to subscribe)
- ThirdIron (Browzine) Libkey Nomad (Jun 2019 onwards)
If you have access to a research library you should investigate options in B) or better yet consult a librarian.
It’s hard to say which extension is better at finding free material, the only half way scientific comparison I have seen ranked Google Scholar button on top.
In any case, I personally favour the official Google Scholar button that uses Google Scholar to find both free and paid versions (available via my institution) myself.
Lazy Scholar which is a hobby project by Colby Vorland is pretty much similar (in fact it was first) to Google Scholar button but with a bunch of additional features e.g Displaying metrics about article, recommendations, extract references etc. I personally find the interface busy, but you might find the features useful.
Unpaywall by non-profit impact story is probably the most well known tool now but does not find copies available via institutional copies, so I don’t think it is suitable alone if you have institutional access. Open Access button is also similar, by a non-profit and does free to read copies only.
The thing to note is that many of the tools in this list , draw from Unpaywall and Open Access button as a source anyway to find free stuff.
Kopernio is actually a commerically owned tool by Clarivate (which owns among other things Web of Science), but currently it is free for use as a business model (probably at institutional level) is not yet available. It tries to find both free to read articles like some of the tools on the list. It’s main claim to fame is that it tries to give you one click access to pdf, as opposed to merely bringing you to the landing page of the article.
Lean Library browser — is a tool that you may encounter if it was purchased by your institutional library. Similar to some of the tools on this list it guides you to free to read articles as well as copies where you might have institutional access.
Lastly Anywhere Access is at time of writing (30th June 2018), the newest of the gang. It is by Digital Science (the same people behind Dimensions- see above). Like Kopernio, it claims to give you one click download to pdfs for both free and subscribed versions.
3. Research literature clustering
Besides keyword searching, are there other ways to discovery what you need?
If you are fortunate to be at a University that has subscribed to Yewno that is definitely worth a try. It allows you to browse by concepts to find what you need.
Barring that, you might want to try Open Knowledge Maps
It’s still keyword based, but the results will be visualized in clusters. This tool isn’t perfect and is still developing but it’s important to note the clustering is just based on metadata and not full text of the article (from BASE or Pubmed).
Another tool that is possibly more interesting is Citation Gecko. Rather then clustering papers by keywords this tools maps relationships between papers with citations. How is this useful?
Phd students are often given a few “seed” papers by their supervisors to use to start their research.
Citation Gecko allows you to input these papers, to create a citation map. You can this to see what papers are cited by these papers (particularly ones that are cited in common by these papers) and conversely papers that cite these seed papers (and again whether there are papers that cite several of these seed papers).
Alternatively you can add in papers you have found yourself by keyword searching (perhaps using the search engines above or with open knowledge graph) and you can map out your literature review to see if there are any unexpected links between the papers you have found.
The nice thing about Citation Gecko is that you can easily add seed papers by searching for papers by title, DOI or importing references in RIS or Bibtex. In fact, you can even import papers from Zotero reference manager!
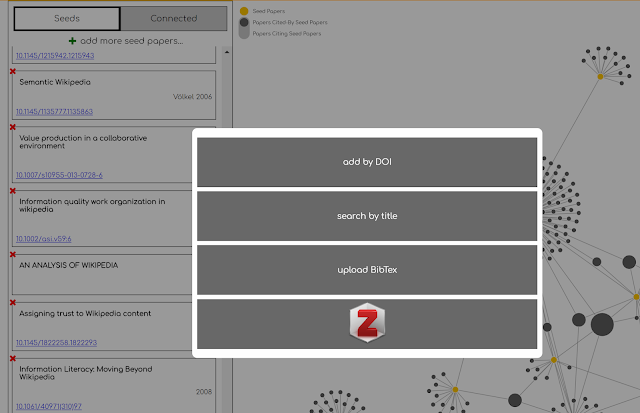
The main weakness is that Citation Gecko doesn’t have every citation and article out there. It draws from open citation data available from Crossref, and Microsoft Academic but the later often times out due to exceeding the API limit.
4. Reference management and reference extraction
Everyone knows about EndNote, Zotero and Mendeley which are probably the big 3 . There are also many interesting ones like F1000workspace, Pubchase (briefly covered here) and dozens more.
If you are looking for something light weight to do referencing, instead of using ad-ridden sites like Citation Machine try ZoteroBib!

Just search for URL, ISBN, DOI etc and add the citation.

“ZoteroBib can automatically extract bibliographic data from newspaper and magazine articles, library catalogs, journal articles, sites like Amazon and Google Books, and much more.”
Another feature that I think is unique is that any citations you add are designed to be stored in the browser cache and remains there until it is deleted. This allows you to go back to them without an account. You can also copy them to the clipboard in various formats (html, RIS) and even save it to Zotero proper. Want to share it online with others? You can general a URL.
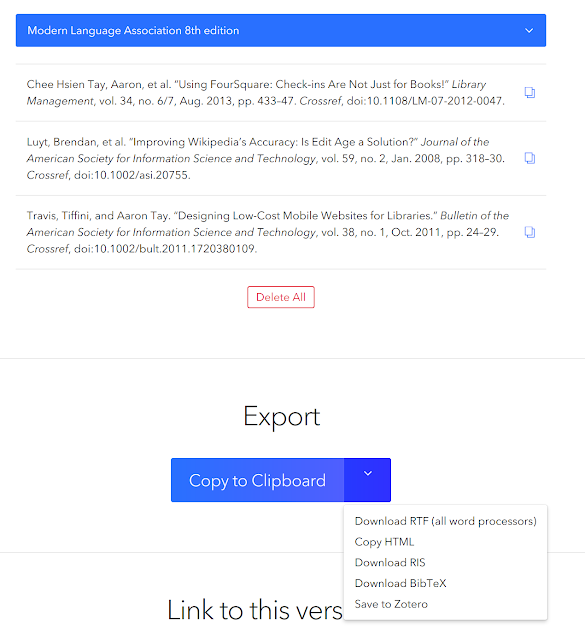
One common task when doing systematic reviews is that you start with a few papers found using keyword searches and then trace references to and from those papers. Add other these papers in a reference manager like Zotero and dedupe.
Citation Gecko is already mentioned as a way to find papers to and from seed papers, but you can’t actually export the papers to your reference managers.
Would be really nice if you could upload a PDF and automatically extract the references in the papers into something like RIS/Bibtex that can be imported into reference managers right?
The tools exists, it is called Scholarcy. One way is to use the API this way
For example, the following URL will produce a RIS file extracting the references in the paper with the URL in bold.
http://ref.scholarcy.com/api/references/download?url=https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5815332/pdf/peerj-06-4375.pdf&reference_format=ris
Even easier would be use the bookmarklet.
Another interesting use is to import this into Citation Gecko either directly via Bibtex or indirectly by importing into Zotero first and then from Zotero to Citation Gecko.
The main drawback of Scholarcy reference extraction is it works only on Open access articles with URLs, or you can use the API (Post method)
An additional note, Scholarcy reference extraction works nicely with F1000workspace because it automatically downloads PDFs of open access items in RIS.
5. Statistical Software
Nowdays a lot of people use R (with R Studio) or Python to crunch statistics and generate visualizations. But what if you don’t want to learn these programming languages?
A free open source statistical package that matches up nicely with the commerical SPSS is JASP
I last used SPSS almost 10 years ago, but I believe JASP’s interface is very similar to SPSS, it’s simple point and click , drag and drop. From what I have read JASP has a slight advantage over SPSS in that it is child’s play in JASP to generate effect sizes as it is just a checkbox away.

JASP generates statistics quickly and easily for you in APA-formatted tables that you can easily copy and paste into Word.
So who are the people behind JASP? The team is funded by a “ERC grant from the European Union, a Vici grant from the Netherlands Organisation for Scientific Research, and permanent support from the University of Amsterdam.”
Other sponsors include Center for Open Science (COS), which explains the support for OSF (Open Science Framework).
As at time of writing JASP is at 0.98 and is developing fast.
Another similar one is Jamovi which like JASP is R under the hood.
It’s currently newer than JASP but has intriguing features to support reproducibility in research . e.g. There is a a feature to export the R syntax that generates the graph. Any options you choose to generate a table or graph is also saved, double-clicking on the graph in Jamovi will show you what options are shown.
6. Data cleaning
Again R and Python are great tools for data cleaning and machine learning. But you want something easier to use? The clear choice is OpenRefine.
It probably the most well known & supported open source, data cleaning tool used by researchers, journalists, librarians and more.
To me Openrefine is great for two things. Firstly it is good at clustering values to clean up dirty free text fields.
It also has reconciliation services , which allows you to clean up data by matching against various souces, most notably Wikidata
Besides Openrefine there are freeware versions of commerical data cleaning tools including Trifica Wrangler, Talend Data Preparation, which has more features that help auto-profile data but I find they can be a bit burdened down by the extra features.
7. Machine learning tools
Deja-view time again — learn R or Python!
Want something easier with point and click?
- Orange (Python based)
- Weka
- Rattle (R based)
- RapidMiner
8. Extra bonus — convert a image graph to data points!
Web PlotDigitizer — Ever found a graph in image form in a paper but you want the data set behind it? Use Web PlotDigitizer to extract the data!
Conclusion
I’ve mostly focused on general tools that can or will be used for most disciplines. But for more specialized tools see DiRT Directory. Tools are always changing and evolving, hopefully my review of these research tools was useful to you.
