More cutting edge — Research tools for researchers — Oct 2020 by Aaron Tay
It’s 2020 and we are settling down into and getting used to life where COVID is the norm. What new research tools have emerged that are worth checking out?
Most of the items are the list are either brand new, or have interesting new features to look out for.
Prior versions —Feb 2020, July 2019, Dec 2018, July 2018,
- Further developments in scite (I) — more advanced search options
- scite visualization trees and scite reference check
- Semantic Scholar improves cited by screen
- More citation mapping tools — Connected Papers , Local Citation Network , Cocites , Papergraph
- 2D Search expands support of more search engines including Lens.org and ERIC + new method to find review papers
- Internet Archive’s Fatcat and Internet Archive Scholar
- Bonus — Ebsco Concept Map, Open Research Knowledge Graph, https://orion-search.org
I’ve left out the ton of experimental tools, built around the release of CORD-19, the covid open research dataset because such tools have very specific use.
1. Further developments in scite (I) — more advanced search options
I’ve written about scite , the interesting citation index that classifies citations by whether they “support” , “dispute” or merely “mention” the paper using machine learning.
As I write this, scite has greatly increased the range of papers included growing to 700 million “smart citations”. It’s hard to compare with traditional citation indexes, but I think traditionally Web of Science, core collection is thought to be about 1 billion, so we are getting close.
scite has been busy during the COVID-19 period, for example they went to work quickly to analyse COVID-19 related papers including preprints and was able to quickly identify preprints that were supported or contradicted
In terms of features, scite added a bunch of features. Some while basic look pretty useful to me. For example advanced search filters ,facets and sorting options all makes it easy to find what you are looking. They have also started to include retraction status , though I am unsure what the source is and how accurate it is.


Other features like citation alerts and ORCID with scite intergration are also nice features.
On the other hand, with scite touting scite badges and journal dashboards, some are worried about the implications of using yet another new and not so well understood metric used for evaluation, with the added complication of Machine learning.
2. scite visualization trees and scite reference check
My own personal view is that while using scite for evaluation metrics might be premature, using it for exploration of literature is probably more acceptable. Granted, there are unclear biases that might result from using scite this way, I would argue it is not much worse than looking at papers using other citation based methods or by relying on black box algorithms of search engines.
As such I look on with great interest with the launch of scite’s visualization feature.
The promise here is that one can explore the literature by expanding nodes by whether a paper has supporting, disputing or even mentioning cites to the first seed paper you start with.
I personally found the interface not too intutive at first, but watching the Youtube video above cleared it up and it soon became second nature.
You click on show visualization and by default it shows up the paper you selected and supporting cites (in green) and disputing cites (in orange). By default mentioning cites are not shown but you can add them.
You then click on a node, and it will display on the top left pane. Click on the small plus icon next to it and you will expand that node.
At this point, I am still mulling over how best to use this.
scite reference checker & Scholarcy preprint healthcheck API.
Another interesting feature is scite’s reference checker.
The idea here is you can upload any paper, probably a manuscript that has not been published and scite will produce a report , similar to the scite entries you see for published papers.

Getting the scite treatment, means it check the references in the page for retractions and you can see how each reference was cited.
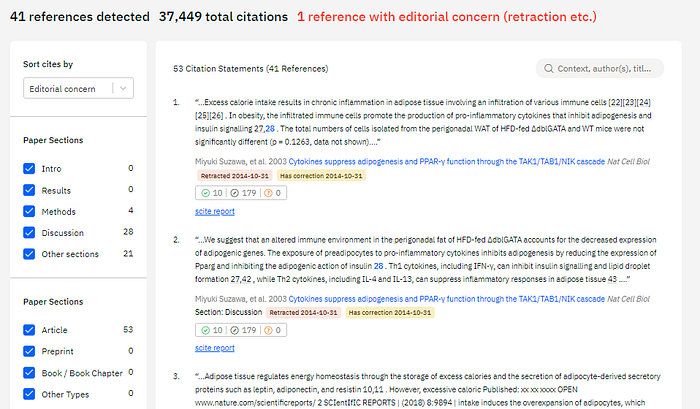
I can imagine this can be useful if you are a peer reviewer and want to quickly get an overview of what is being cited and how, or if you are the author himself who wants a overview before submission to journals.
A somewhat interesting tool to use together with this is Scholarcy preprint healthcheck API which I mentioned in the last report.
It extracts affiliations, highlights key findings, figures out study subjects, statistics , tries to identify sections like data availabilty, ethical compliance etc.
There is some overlap in that it also checks for retractions. In terms of references it extracts and runs them against various whitelists or sources like DOAJ and Crossref, which I guess can be useful if you want to filter references by the reputation of the source.
3. Semantic Scholar improves cited by screen
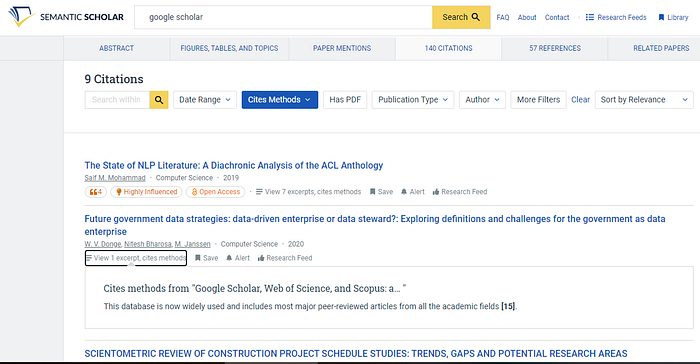
The cited by screen in Google Scholar is IMHO one of the strongest features of the search engine. It allows you to set up an alert, and more importantly allows you to “Search within citing articles”, a very powerful feature for quickly filtering down to citations of interest when there are thousands of citations for a seminal paper.
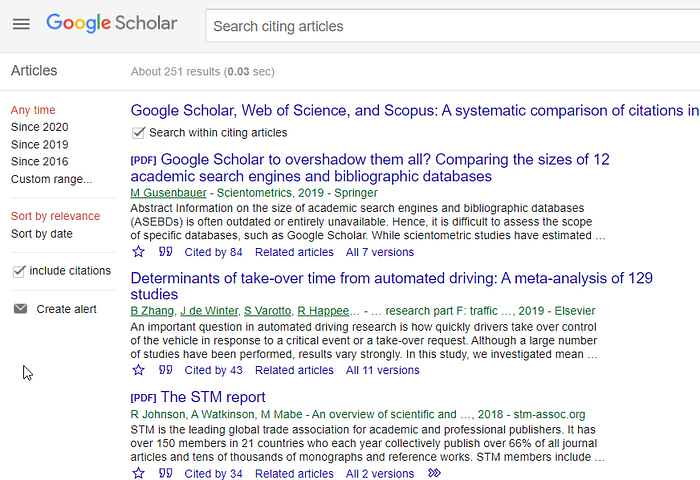
Part of why ”search within citing articles” is so powerful in Google Scholar is that Google Scholar has full text most of the time, so you could search 1,000+ citing articles for one fairly specific term, something you can’t do for most other search engines due to lack of full text.
That said other search rivals like Semantic Scholar have more metatdata. So the new feature allows you to search within citiations but also allows you to filter by
- data range
- citation type (cites all, cites background, cites method, cites result)
- publication type (book, journal article etc)
- journal/conference title
- Field of study (e.g. Art, biology)
- Author
- and more.
I’m still trying it out but I suspect #2 citation type and #5 field of study might be most interesting filters when you have a lot of citations to go through. That said, it is kinda fustrating that while the other filters display only options that have at least 1 item, the “Fields of Study” list all and if you click on some of them you get no results.
4. More citation mapping tools — Connected Papers, Local Citation Network, Cocites, Papergraph
In past editions of this report, I’ve talked about a new breed of citation mapping tools — represented by Citation Gecko. In general, such tools require that you have multiple seed papers to find other related papers using bibliometric relationships.
This year, I noticed a couple of new ones — namely Connected Papers, CoCites and Papergraph, Local Citation Network that work like Citation Gecko but require only one paper.
EDIT : Some like CoCites , now allows you to select multiple papers as seeds.
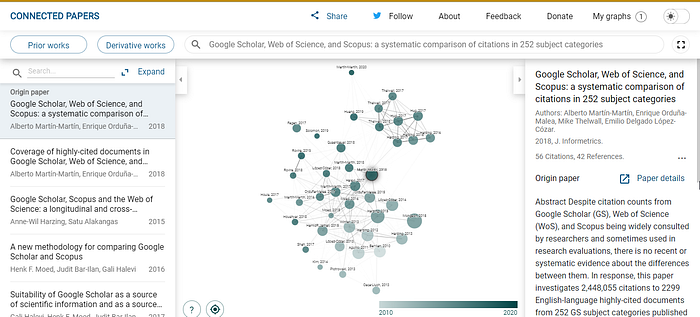
Connected Papers is a particularly nice one, where it can try to generate papers that are similar to one given paper, based on a similarity function based on the concepts of Co-citation and Bibliographic Coupling.
Because it finds papers that are similar based on both whether they are cocited and by similarity of reference lists (Bibiliographc coupling), it can work for some very new papers, even if the papers have had little to no citations, unlike tools like CoCites which are based just on cocitations.
The other nice feature of Connected Papers is that once it finds 40–60 similar papers, you can then click on “prior papers” where it tries to identify seminal papers based on what are the most common papers cited by those similar papers or do the reverse and click on “Derivative works” which may find you review or survey papers.
All these tools leverage on existing open sources of metadata and citations, in particular Pubmed (Cocites), S2ORC and the older Semantic Scholar Open Research Corpus (Connectedpapers, Papergraph), Microsoft Academic Graph (Local Citation Network) and Crossref (Citation Gecko and Local Citation Network)
For more in-depth comparison of these tools
5. 2D search expands support of more search engines including Lens.org and ERIC + new method to find review papers
2Dsearch is a tool that helps you create and visualize complicated nested boolean searches such that you are less likely to make a mistake. Of course, many search engines even academic ones today have limited support of Boolean.
But I was talking with Tony Russell-Rose of 2Dsearch earlier this year and it occured to me that Lens.org which is full of structured fields and features powerful boolean searching would benefit beautifully from the 2Dsearch treatment. I was gratified that they went ahead so support Lens.org, and it was all that I could have hoped for.
In — Finding reviews on any topic using Lens.org and 2d search — a new efficient method, I created a well tuned and tested search template in 2Dsearch that anyone coild modify to quickly find meta-analysis, systematic reviews, review articles of topics that interested them.
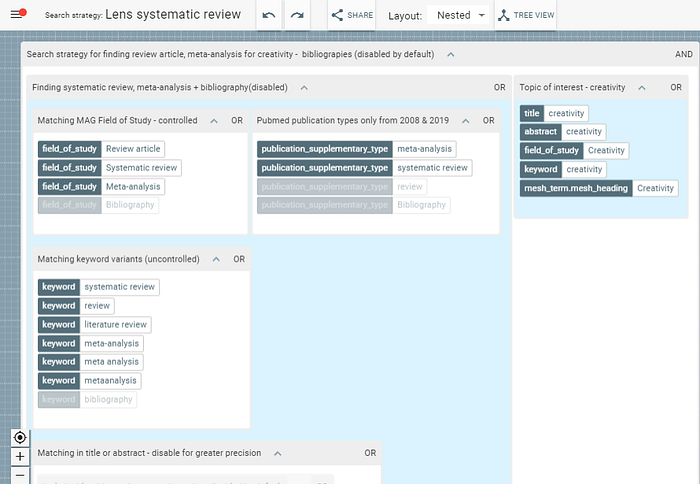
By simply changing the topic that is set to “Creativity” to your topic say “Servant Leadership”, you could get a high recall, high precision search in Lens.org.
For more details
6. Internet Archive’s Fatcat and Internet Archive Scholar
Most of you know about the Internet Archive (in particular the Wayback Machine) but did you know “the Internet Archive has been working on a Mellon-funded grant aimed at collecting, preserving and providing persistent access to as much of the open-access academic literature as possible.”
In fact, they have been going about this for a while, but the recent preprint — Open is not forever: a study of vanished open access journals , shone a torchlight on the issue of journals that disappeared from the net but were not properly preserved (not all Journals are covered under LOCKSS or similar programmes).
This blog post describes the top down process that resulted in Fatcat
Top-Down: Using the bibliographic metadata from sources like CrossRef to ask whether that article is in the Wayback Machine and, if it isn’t trying to get it from the live Web. Then, if a copy exists, adding the metadata to an index.
It also describes a bottom up approach that reminds me of what Google Scholar does. This is of course very difficult.
Bottom-up: Asking whether each of the PDFs in the Wayback Machine is an academic article, and if so extracting the bibliographic metadata and adding it to an index.
I havent done a full review of Fatcat yet, but it is essentially a
versioned, publicly-editable catalog of research publications: journal articles, conference proceedings, pre-prints, blog posts, and so forth. The goal is to improve the state of preservation and access to these works by providing a manifest of full-text content versions and locations.
Among other features, it tracks at the file/item level whether the article has proper preservation, whether it is via a dark archive like (LOCKSS) or a bright archive (e.g. Hathitrust, Internet archive itself) by drawing data from sites like Keepers Registery etc.
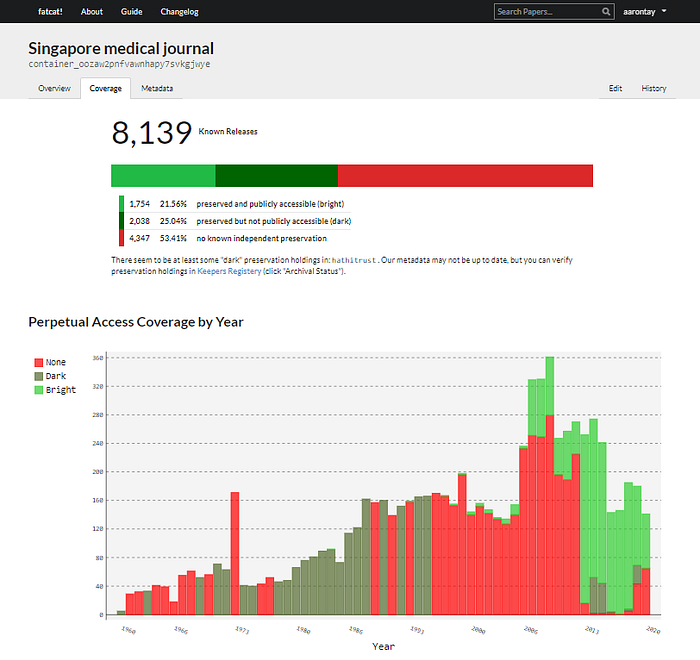
Besides Fatcat, the internet archive also has a Internet Archive Scholar (currently at https://scholar-qa.archive.org/).
How does it differ from Fatcat? In essence, Fatcat will list all items even metadata only items, while Internet Archive Scholar shows only full text.

I wonder it might be a good idea to complement your Google Scholar searches with this to see if you missed out anything.
7. Bonus — Ebsco Concept Map, Open Resarch Knowledge Graph, https://orion-search.org
We are constantly seeing new research tools relating to discovery, here are some others I encountered. I will add them with little commentary.
Open Knowledge Research Graphs , on paper this isn’t very different from other Scholarly graphs out there like OpenAire Knowledge graph , Project Freya PID graph but the key point I think is open knowledge research graphs not only captures paper metadata e.g. title, author, doi, journal title but also the paper’s contribution, methodology etc.
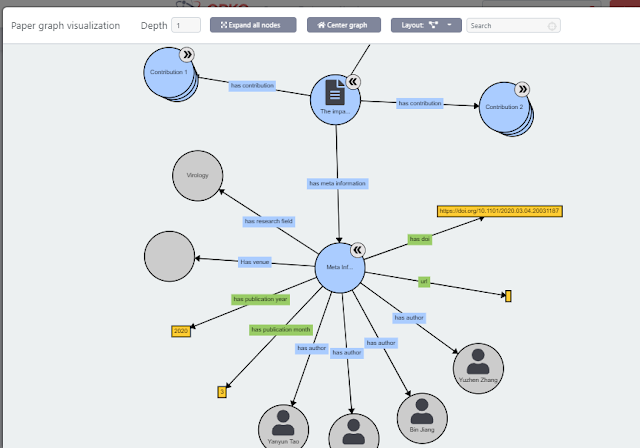
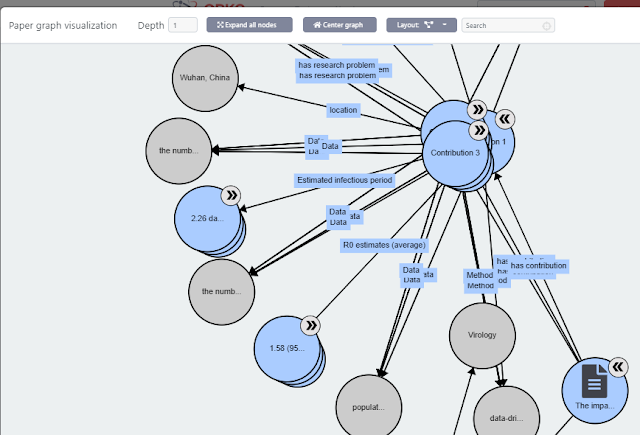
This allows interesting features like auto-generation of comparison tables

Interestingly, while this seems to be expecting humans to mark up the contribution, startups that are built around Machine learning like Scholarcy are trying the approach of using Machines to do most of the work.
This mirrors to some extent the work done by Crossref versus the approach taken by Google Scholar and Microsoft Academic which work more by trusting machine extraction.
Last but not least is the very fancy https://www.orion-search.org/ . The visualization interface remdins me of playing a 4X space strategy game where you can pan and zoom in the 3D space.
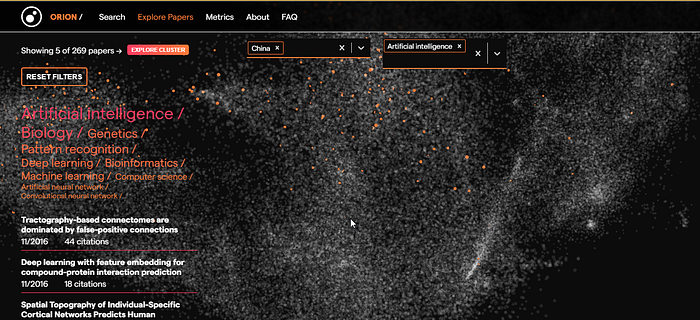
Orion also has a unusual metrics with axis “Research diversity” and “gender diversity”.
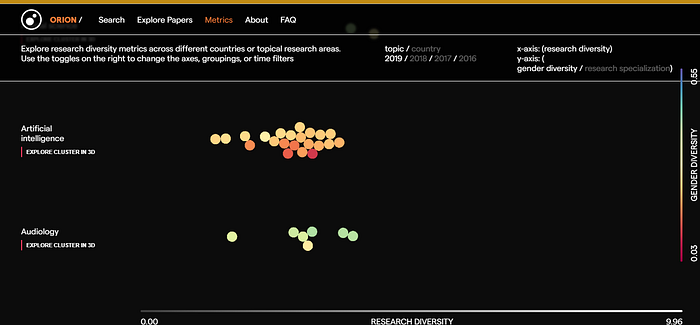
Do note the Orion demo is restricted to only a certain set of papers and cannot be used as a cross disciplinary database. “Using this Orion deployment as an example, we queried MAG with a journal name, bioRxiv, to collect all of the papers published on its platform”
