4+1 Different Ways Large Language Models like GPT4 are helping to improve information retrieval
Warning: I am not a data or information scientist; this is a new area I am trying to learn about

The rise of large language models, such as GPT-3, GPT-4, ChatGPT, and BERT, has dramatically improved information retrieval in recent years. With their natural language capabilities, these models are enabling search engines to deliver more relevant and accurate results as well as enhancing the overall user experience with new features.
In fact, there is more than one way this is happening, so in this blog post I will list out some of the main ways they are being used.
We will discuss among other things
1. Use of contextual embeddings from large language models to improve relevancy rankings
2. Using Generative AI/Language models alone to generate answers
3. Q&A systems that combine use of search/retrievers to get context from external sources which is then used by the generator (e.g., chatgpt) to generate an answer.
4. Querying individual paper or “chat with pdf “ type features.

1. Improving of relevancy of results — Semantic/Neural search
This is the most understated and least noticed improvement that large language models bring to search engines as they tend to be done under the hood and are not noticeable to users.
Language Models at its core are used to generate statistical models that can tell you given a sequence of words, what the next most probable words are.
State of art language models based on the Transformer neural net architecture result in near human natural language understanding which is useful for interpreting search queries.
In fact, many search engines including Google use state of art contextual/dense embeddings from language models such as BERT to improve relevancy ranking.
Use of such contextual or dense embeddings for relevancy ranking is often called Semantic Search/Neural search as compared to the traditional lexical search/keyword search.
For more details — Did you know? How embeddings from state of art large language models are improving search relevancy,
They tend to have the following advantages
- Semantic Search/Neutral Search automatically “understands” the meaning of query and documents (via embeddings) so it can match relevant documents even if keywords do not match
- Semantic Search/Neutral Search considers order of words in text
- Semantic Search/Neutral Search might even be able to handle multi-lingual queries/matches
Language-Agnostic BERT Sentence Embedding
Their main disadvantage is they may pull out documents that do not have many keywords in common with the query because they match “meaning” rather than strictly keyword.
An example of an Academic Search engine that uses language models for relevancy ranking is Elicit.org which uses a type of sentence transformer model embedding that
perform semantic search by storing embeddings of the titles and abstracts using paraphrase-mpnet-base-v2 in a vector database; when you enter a question, we embed it using the same model then ask the vector database to return the 400 closest embeddings.
Most systems don’t use Semantic/Neutral Search completely and may instead be hybrid systems that combine Lexical/keyword search results and create rankings which merge both types of results. Part of this is for predictability (keyword searching is more predictable), the other reason is for computational speed/cost as calculating large dense embeddings on the fly or storing in databases can be expensive.
However, we will leave aside this use of Large language models, because even when search engines implement this, the results are still displayed typically links to relevant documents.
But Large Language Models such as OpenAI’s GPT models, GPT2/GPT3/ChatGPT/GPT4 (decoder only transformer models) are also generative AI that can generate answers, what happens when we incorporate them into information retrieval?
A model of information retrieval and generative large language model
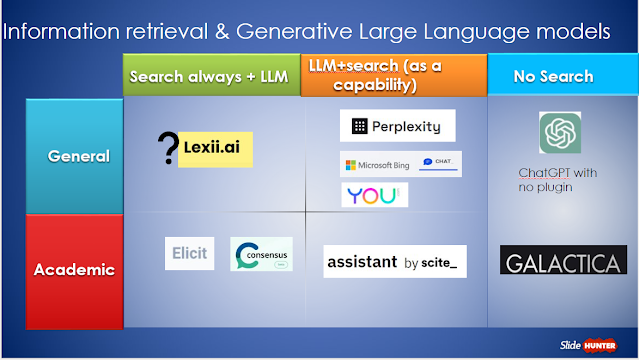
2. Using Generative Large Language Models to answer questions with No search (extreme right column).
Ever since OpenAI launched ChatGPT (and even prior to that for GPT2 and GPT3), one of the use cases people have tried is to ask it questions to generate answers. It is important to note that while answers are generated, no search in the traditional sense of query matching to documents is involved.
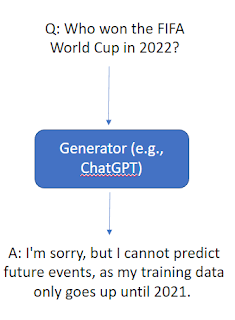
Below shows an example.
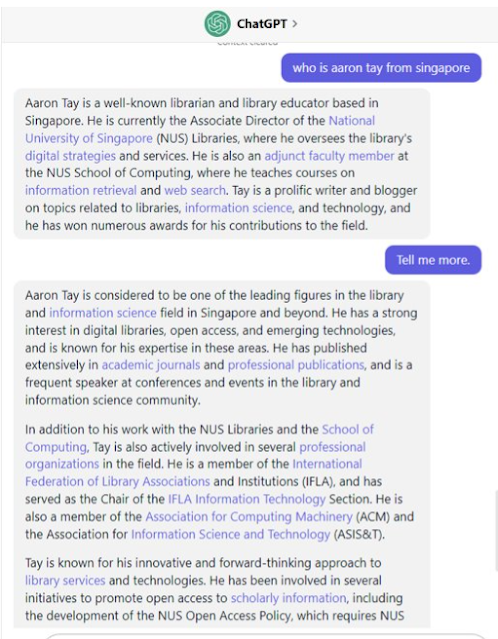
ChatGPT without search makes up things about me, I wish I were that distinguished!
By now you will know that Large Language Models tend to make things up or “hallucinates”, even though the newer ones like GPT4 are much less likely.
Why do such hallucinations occur?
To understand why Large Language Models do not have perfect recall, it is important to note that they do not store all the training data they “see”, in fact all they do is learn weights in a neural network (Transformer) as they are trained in a self-supervised way from the huge amounts of text that is thrown at them.
In Crucial difference between web search vs ChatGPT, the author claims that the CEO of OpenAI — Sam Altman says that
ChatGPT is actually more about human-like cognition than providing and even collating regurgitated content… The reason that LLMs can’t always regurgitate — which would be useful for web search — but makes them prone to hallucination is that nowhere in the neural network is a single piece of training data stored verbatim. That’s not how neural networks work. They are actually kind of compression / decompression algos.
In other words, Large language models are good at generalizing/pattern matching but are not meant to memorize answers or facts. Kinda like a human in fact.
Unlike a traditional database search where the words in documents it is trained on are stored in an inverted index, for LLMs like ChatGPT all training data is discarded and only the weights are stored.
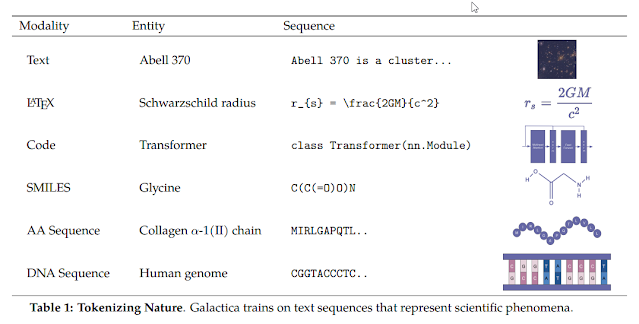
There has been some speculation on how much academic content, journal has been included in such large language models but for sure Meta’s Galactia.org subtitled — “A Large Language Model for Science” was trained just on academic content and even has special features to recognize
- Math Formulas (LaTEX)
- Code
- DNA
- Chemical Compounds (SMILE)
- References
Being built as a generate language model like OpenAI’s ChatGPT you can prompt it and it will continue as per normal. Below shows a prompt to attempt to complete it with a reference
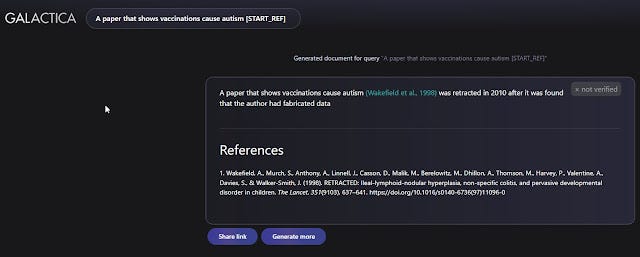
And yes, you can prompt it to write a whole scientific article.
When it first launched, the Galactia.org allowed you to run prompts directly from the website exactly like ChatGPT, but it was such a controversial system that the online web demo was taken down in just 3 days.
Can you guess why? Similar to ChatGPT it made up a a lot of plausible sounding but wrong disinformation in articles it wrote. Today you can still run this model for free, but you will need to download the model and run it locally on your computer.
This isn’t particularly difficult, requiring only a few lines of code, but the bigger models require more powerful computers to run.
Some have protested about the double standards where there was so much hue and cry over Galactia.org vs less so for ChatGPT when both generate falsehoods, but I suspect part of it is matter of degree, and more importantly, Galactica was positioned as a Science generation system where people expect higher standards.
3. Generative Large Language Models that has search as a capability (middle column)
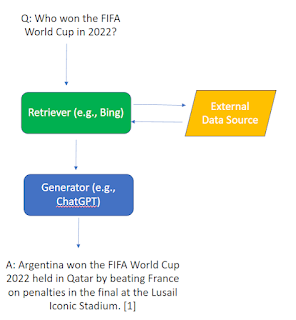
Retriever-generator model that is getting popular e.g., Bing+Chat, Perplexity
As we saw earlier, using ChatGPT or it’s academia equivalent Galactica.org tends to result in hallucinations.
Even if it does not, Large language models as the name suggests takes a long time to train and using it to answer questions will mean it will not have current information. For example, as of time of writing OpenAI’ chatGPT and GPT4, will not be able to answer questions for events in 2022. For example, if you ask who won the FIFA World Cup in 2022 , ChatGPT refuses to answer, GPT-4 usually refuses as well, but may sometimes makeup answers.
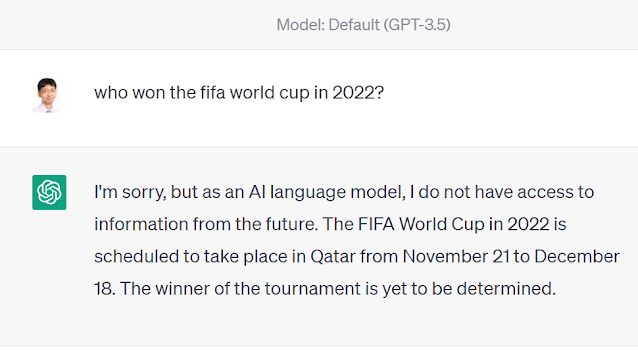
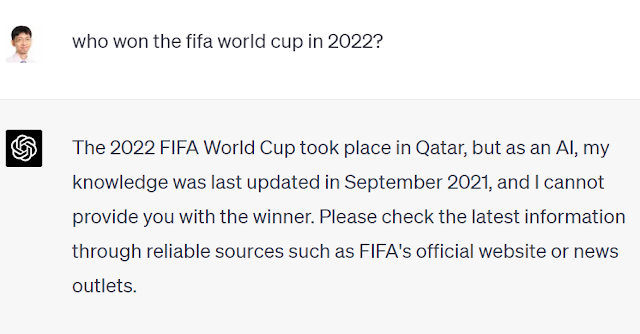
Worse yet, even if ChatGPT or GPT4 gives an answer there is no way to check the answer. You can ask for references, but it may make those up too!
So, what is the solution?
As many people have found out or figured out independently, a solution for all these problems is to incorporate search. By creating “a version of ChatGPT that can use web searches to ground its answers with what it finds on the internet”, you can find a far more reliable answers than just using GPT-4 alone.
The technical term used sometimes is Retriever-augmented Large Language Model
The current most famous example is the Bing+Chat search. Below shows it searching for the appropriate webpages then extracting and using the content to generate the right answer.
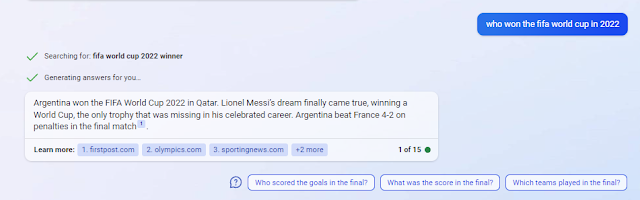
It even shows links/citations you can use to check the answer.
Prior to this launch, another web search engine — Perplexity.ai was available which did pretty much the same thing combining general web search with OpenAI’s generative Language models to generate answers. Also similar is You.com.
To better understand how the answer is generated let’s look at a question I asked at Perplexity.ai on the size of Google Scholar.
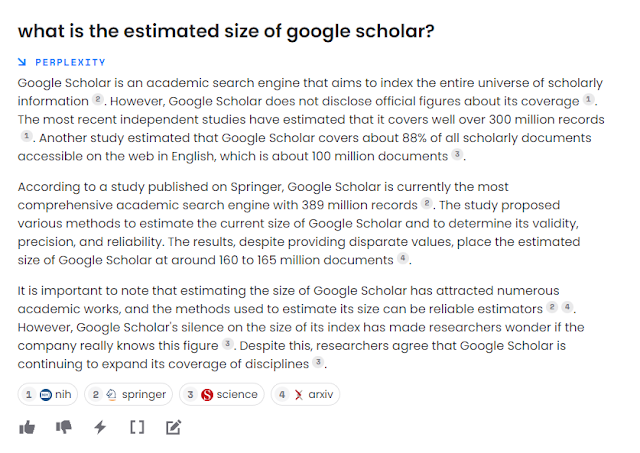
The results are excellent, with citations to webpages. But Perplexity shows even more detail if you click on view sources button (the square brackets), you can even see the extract sentences used to generate the answers!
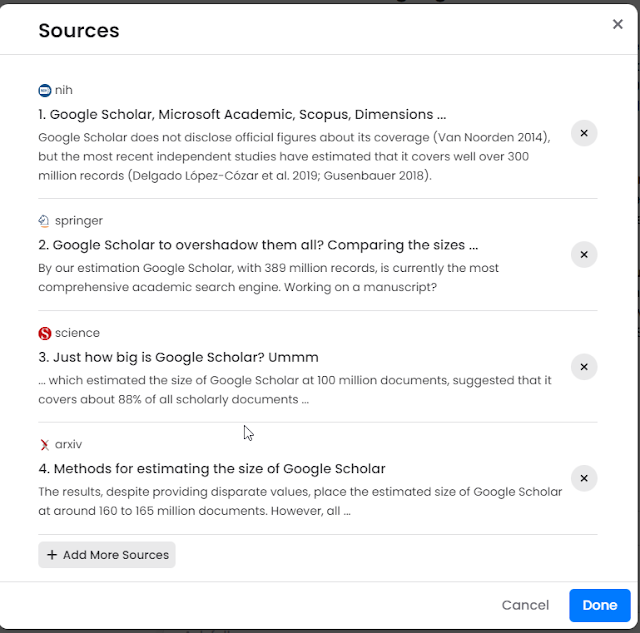
In fact, Bing+Chat almost certainly uses a similar technique and is prompted to generate answers using text segments of different documents (sometimes called context) rather than the whole document, but only Perplexity shows you exactly what context is used to help answer the question.
More recently, OpenAI announced that ChatGPT was getting plugins to extend its capabilities and among the various capabilities including access to tools like Wolfram Alpha (for mathematics & other functions), Code interpreter for Python etc and web search.
It is important to note that these systems are Generative Large Language Models first and foremost but have the capability to search. They do not always have to search.
For example, here is me having a nice chat with Bing+Chat, where no search is involved.
Like Bing+Chat are the already mentioned Perplexity.ai as well as You.com which are LLMs that are capable of searching.
The academic version of these tools is the newly launched Scite.ai Assistant, which uses ChatGPT API as the language model but searches over the metadata (title and abstract) and citation statements/contexts for relevant text to generate the answer.
Prior versions of Scite offered a “Ask a question” beta feature. The main difference between that version and the current version is that this earlier version did not generate answers but rather extracted or highlighted parts of the text that it felt answered the question. This is sometimes known as extractive (as opposed to generative) Q&A, see Consensus.app later.
Below I prompt scite assistant — “write an essay explaining why you should not use google scholar alone for systematic reviews”
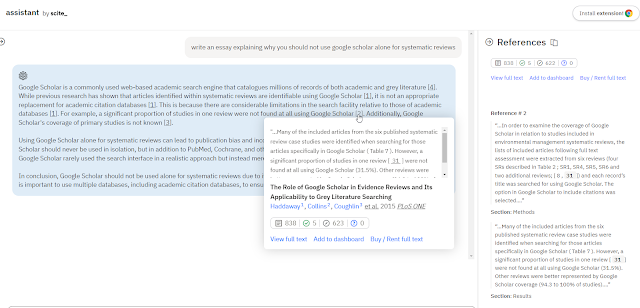
Similar to the general web versions, scite assistant searches and uses the top ranked text segments in documents to generative answers with citations.
I won’t go into detail how to interpret these except to say the references generated in this answer come in two forms.
Firstly, it may be citing a paper’s abstract.
More importantly, it may be citing text in a citation statement. You can tell this is so when the citation mark is in bold.
In the second case, scite’s answer is coming from text made by the paper’s author describing another paper or citation statement. In such a situation you are relying on a secondary source or doing indirect citation, which style guides say to avoid when possible. I highly recommend actually checking the citation to ensure the citation statement is accurate.
Similar to Bing+Chat, scite assistant does not always search.
scite.ai assistant writes a poem without searching
To search or not to search that is the question
Because Bing+Chat, Perplexity.ai, Scite assistant are full-fledged large language models that may sometimes search, you might be curious to know how they decide to search and when not to.
The answer varies, for example OpenAI’s unreleased WebGPT would copy human demonstrations of search
Bing+Chat talks about the Prometheus system with a “Bing Orchestrator”.
As such, each of these language models with search capabilities may differ in tendency to search for answers.
In terms of actual performance, deciding to search in response to some prompts might improve performance e.g. while in other types of prompts, searching might lead to the task failing.
For example, I have asked Bing+Chat to play a historical character with views on <hot button issue> and Bing+Chat would search find no results and refuse to continue, while not searching would complete the task e.g. ChatGPT easily fulfills the request.
4. Search (always) engine with Large Language models (left column)
These are outright search engines only, or traditionally called Q&A systems that only search. ‘
These tools can’t do code completion, write poems etc.
They take all input such as search queries, try to find relevant documents and extract the answers.
This can be in the form of answers from the document (Consensus.app) or it may generate a paragraph of answers (Elicit.org)
Unlike say the new Bing+Chat, every query you enter in Elicit is interpreted as a search. The large language model is used to generate answers (see top left text) or may be used to extract information about individual papers such as main findings, methodology, region etc.
See here for a more complete review.
Consensus.app is also another traditional Q&A system that only searches.

The main difference is that Consensus.app unlike Elicit.org and every example above, is it does not generate new answers, instead it just extracts actual text from the paper without rewriting it and presents the part of the string it thinks is the answer.
This model is remarkably similar to the retriever-generator model from above, the only difference is that it uses a “reader” (instead of generator) to extract the extract parts of the text that may answer the question. It takes exactly the words in the text and does not summarise or paraphrase at all as compared to using a generator.
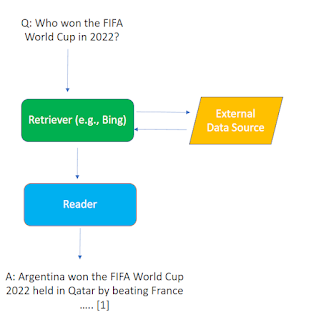
This model uses a reader instead of a generator , so it extracts exactly what is in the text
This avoids hallucinating even more, but answers tend to be less friendly, because it can only extract exact answers from text if they exist.
5. Language Models querying of individual papers
So far, the examples involve searching across more than one paper, but it is of course possible to use the Natural language understanding and summarization capabilities of large language models to ask questions of individual papers.
Both Elicit.org and Scispace and a host of “Chatpdf” services allow you to query individual papers, if they are indexed full-text or if you upload the paper.

Ask questions of individual papers in Elicit.org
Scispace includes a “Copilot” where you can highly sentence to be explained to summarized to you.
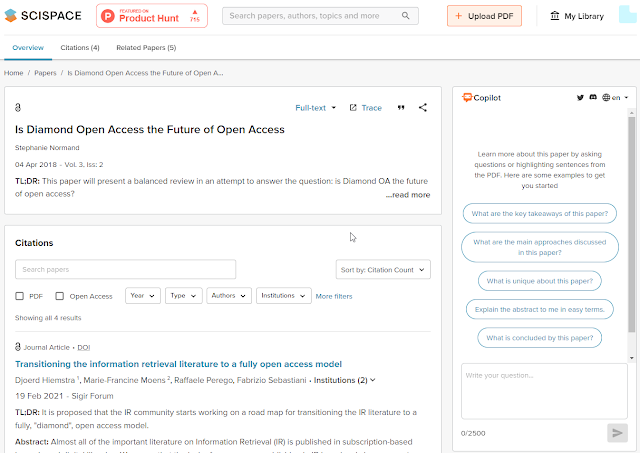
You can even ask the copilot to explain figures or tables by dragging and dropping them!
I am also starting to get queries from researchers who want to do something like this via ChatGPT
1. Find all papers in Journal X from 20xx-2023.
2. Filter to topic X
3. Summarise each paper
Using ChatGPT directly to do this is obviously not a good idea since it may not “remember” all papers in journal X as ChatGPT isn’t built as a formal database of papers and at best can surface a few papers it associates with the journal (just as a human might remember a few papers in a journal).
Clearly what you want is to search with a conventional search engine that can reliably pull out all paper on Journal X, then pass the text over for ChatGPT or similar Large Language Model to summarise.
Elicit.org would be ideal for this since it can generate a table of studies with columns for various items e.g. findings, but it currently does not seem to allow a search restricted by journals. It might not also have the full-text of the papers in the journal.
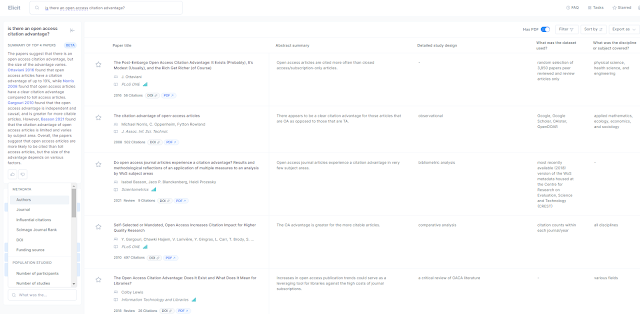
Elicit creates a table of studies based on extract information from papers
Conclusion
We are in the incredibly early days of trying to integrate capabilities of large language models into search engines. There are a lot of open questions on how users will use these features and what affordances they will need or expect in new search engines.
For example, in terms of UI, it seems currently systems like Bing+Chat, Perplexity and scite assistant are giving priority and focus to “chat”, and showing the generated answer by such systems up front and center with the possibility of continuing to chat and search results are fairly hidden.
However, it seems unclear to me if this is the best way. One alternative could have a UI that combines both the generated chat answer and traditional search results, which can be used if you are not happy with the generated answers.
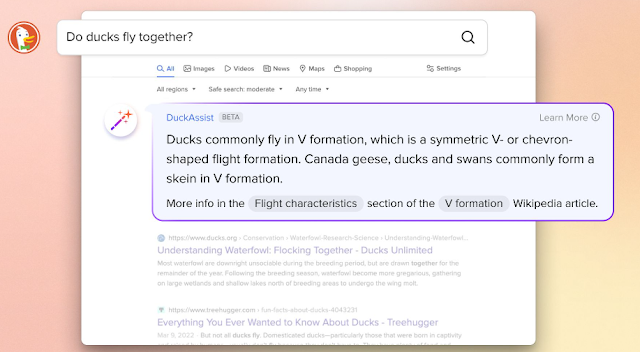
For example, DuckAssist plans to just put the generated answer on the top of the paper followed by traditional search results, like how Google sometimes provides instant answers at the top.
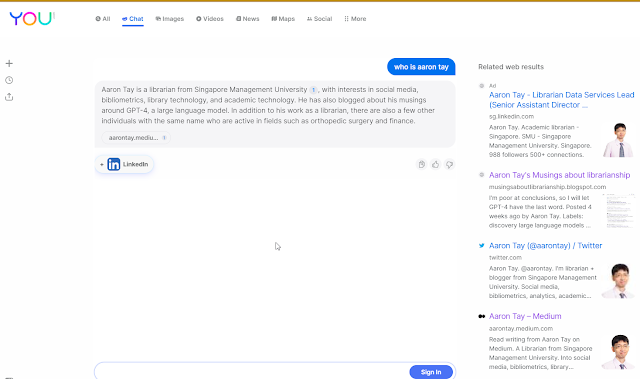
You.com shows yet another layout, where the generated answer is shown up front but the sidebar contains search results.
Of course, one could also do the reverse and have the main part of the screen showing traditional search results and the sidebar showing the generated answer, similar to Bing Toolbar.
I can also imagine other possibilities like giving you the ability to look at a search result page, select five links that you think are interesting and ask the system to generate an answer.
Many more ideas to come….
Post-writing note — Of course the most important question about such systems is how good or accurate they are at generating answers.
As I write, most of the research and testing is still on using ChatGPT or LLMs “naked” and there is little research on the effectiveness of AI powered search tools such as Bing+Chat or Perplexity that combine generative answers with search.
Here are two

